

How AI Agent memory actually works
Context windows forget, vector stores remember, and somebody still has to own the bytes

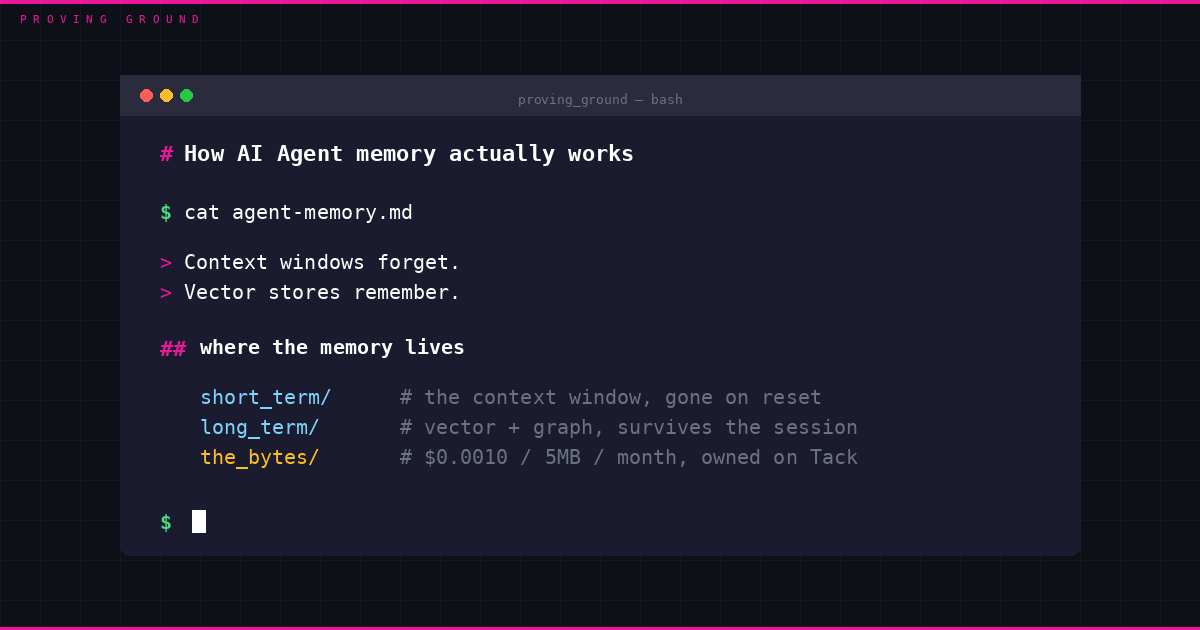
AI Agent memory works in two layers. There is short-term memory, which is whatever fits inside the model’s context window during a single run, and there is long-term memory, which is everything the Agent writes to an external store so it survives the session ending. The short-term layer is fast and disappears the moment the context resets. The long-term layer is where the durable stuff lives, usually a vector database for semantic recall and sometimes a graph database for relationships between facts, and it is the layer most teams underbuild. By 2026 the dominant production pattern is hybrid, a short-term episodic buffer sitting on top of vector plus graph retrieval, because no single structure covers everything an AI Agent needs to remember. What almost nobody specifies is where those long-term bytes physically sit and who pays to keep them there, which turns out to be the part that breaks when an Agent has to run on its own.
What short-term and long-term memory actually mean for an AI Agent
Short-term memory is the context window. It holds the current conversation, the last few tool outputs, the active goal and the intermediate reasoning the model is using to decide what to do next. It is quick and it is local to the run, which is exactly why it is fragile. When the window fills up or the session ends, that working state is gone unless the Agent deliberately moved it somewhere first. People treat the context window as memory because it behaves like memory inside one session, but it is closer to RAM than to a hard drive. Nothing in it persists by default.
Long-term memory is what you get when the Agent writes selected pieces of that working state out to an external store so a future run can read them back. The research literature, borrowing from cognitive science, splits long-term memory into three rough types. Episodic memory records specific past events, what happened, what the Agent did and how it turned out. Semantic memory holds general facts the Agent has learned and can reuse, like a user’s preferences or a stable piece of domain knowledge. Procedural memory captures how to do a recurring task, the learned routine rather than the one-off event. An AI Agent that remembers you across weeks is reading episodic and semantic memory back into its context window at the start of each run, then writing new entries at the end.
How retrieval works once the memory lives outside the model
The reason long-term memory needs more than a text file is retrieval. An Agent cannot reload everything it has ever stored into a context window, so it has to fetch only the relevant pieces, and “relevant” is a fuzzy match rather than an exact key. That is what a vector database does. Each stored memory gets converted into an embedding, a numeric representation of its meaning, and at recall time the Agent embeds its current situation and pulls the stored items that sit closest in that space. This is why an Agent can surface a note you wrote three weeks ago that never shared a single keyword with what you just asked. Graph databases handle the other half of the problem, the relationships between facts, so an Agent can traverse from a person to the project they own to the deadline attached to it rather than guessing those links from similarity alone. Most serious deployments in 2026 run both, a vector store for semantic recall and a graph for structure, with the short-term buffer in front of them. Frameworks like mem0, LangGraph, Letta and Redis exist mostly to wire that pipeline together, the extraction step that decides what is worth keeping, the consolidation step that refines it and the retrieval step that reads it back.
Where the memory actually lives, and why that breaks for autonomous Agents
Here is the gap every memory diagram skips over. A vector database stores embeddings, but embeddings still point at bytes, the original document, the image, the working note, the per-user state the Agent is keeping. Those bytes have to sit somewhere durable, and that somewhere has historically been a cloud bucket behind an account, an API key and a credit card. That assumption is fine when a human set the Agent up and pre-funded everything. It falls apart the moment you want an AI Agent to manage its own memory, because the Agent cannot open an account, cannot rotate a key and cannot sit through a billing signup. The memory layer everyone designs around quietly depends on a human standing behind it holding the storage relationship together.
This is the problem Tack was built for. It gives an AI Agent a memory layer it can stand up and pay for by itself, no human holding the storage relationship together. Tack is the agent-native storage product from Inference Room, built on Taiko, and it stores the bytes behind an Agent’s memory without any of the account scaffolding. The Agent writes a private object to Tack, pays a fraction of a cent in USDC inline with the request through x402, and gets back an id that only the paying wallet can read. A 5MB memory object held for a month settles at $0.0010, with no signup, no API key and no human in the loop. The object is wallet-scoped rather than sitting at a public address, so per-user session memory, drafts and working notes stay private to the Agent that owns them, and it expires after the paid duration so memory is something the Agent rents for as long as it needs it. The wallet that pays for the Agent’s compute is the same wallet that owns its memory, which is the shape autonomous memory actually needs.
Tack is the agent-native storage layer from Inference Room, built on Taiko and settling in USDC via x402 with no accounts, and it gives AI Agent memory a durable place to live that the Agent can pay for and own by itself. It is open at tack.inferenceroom.ai now.
This post is exploratory and does not represent a specific roadmap.