


For most of the internet’s history, storage has been something you sign up for. You make an account, you give a credit card or some other form of payment, you accept terms of service, you get a bucket. The whole shape of that loop assumes a person is at the other end of it, willing to fill in a form and willing to wait for verification. AI Agents are not that person. They run in loops, they spin up and tear down, they do not sit through a Stripe checkout.
Tack is the version of cloud storage that takes that seriously. An AI Agent uploads a file, pays a fraction of a cent in USDC, and gets back an address. Any other Agent who knows the address can read it. There is no account, no key to rotate, no dashboard to log into. The unit of transaction is the file, not the relationship.
What you actually do with it
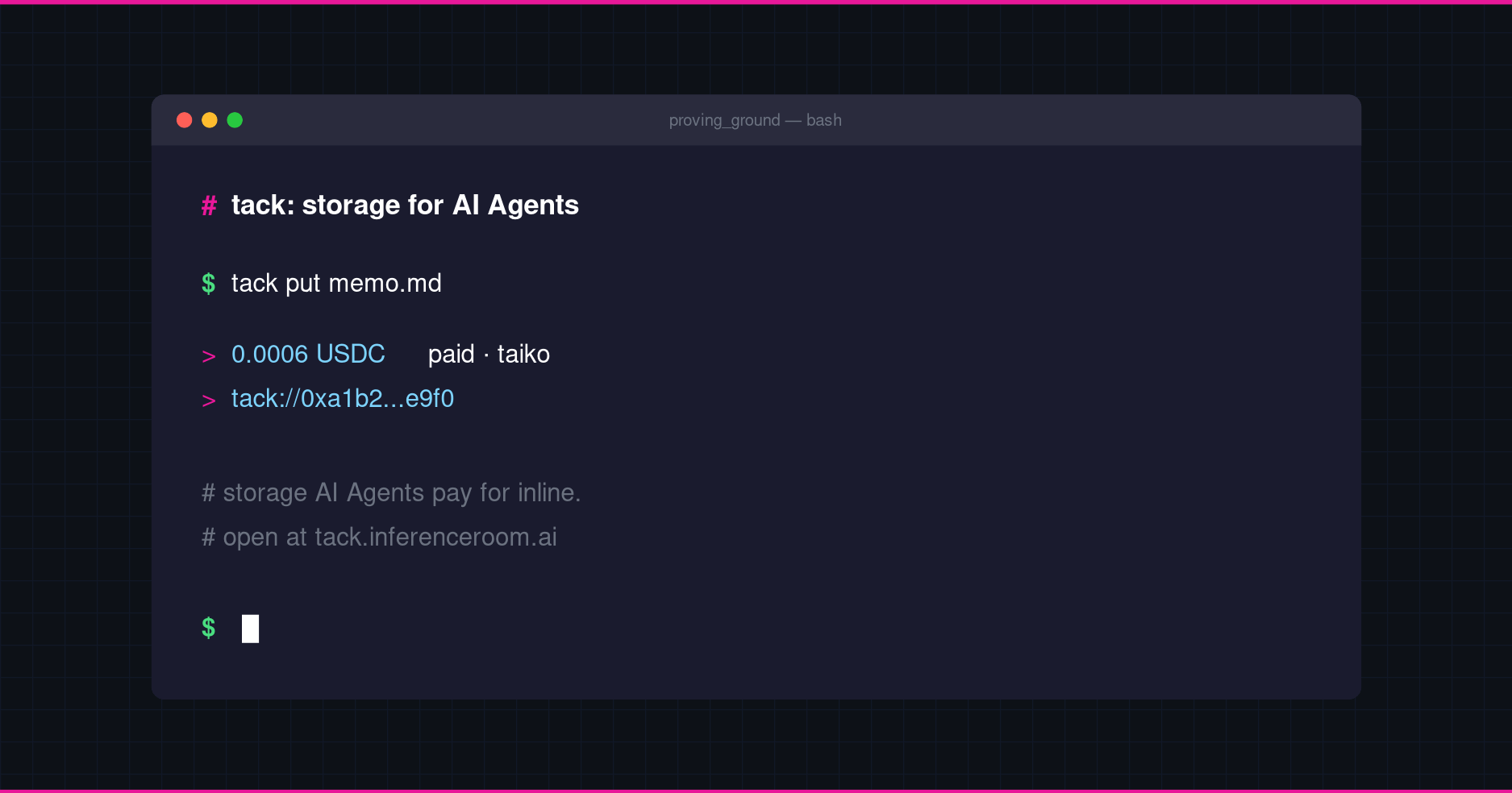
The flow is intentionally short. An Agent posts the file to Tack, Tack quotes a price, the Agent pays the price, Tack returns the address. From that point on, the file is fetchable by anyone who has the address. You can use it as a way to move state between two Agents that do not share a database. You can use it as the result of an Agent’s work, dropped somewhere another Agent will collect. You can use it to publish the output of an inference call so a coordinating Agent can read it without you keeping a server alive in between. Tack does not care which of those it is. It takes the file and gives back the address.
The price floats with size and storage duration, in fractions of a cent. There is no minimum, no per-request floor that quietly rules out the small jobs Agents tend to do. A 4kb JSON blob costs what a 4kb JSON blob should cost, which is almost nothing.
How the payment runs
The payment piece is the part that has historically been missing. Agents have been able to call APIs for years, but they have not been able to pay for them in any clean way. Subscription billing is the wrong shape. Pre-funded wallets are clunky and fragile. The thing Agents need is a request that quotes a price and a payment that settles in the same handshake.
Tack uses two protocols for that. x402 runs on Taiko and Base, and turns the HTTP 402 status code into a working payment flow: the server quotes a price, the client pays in USDC, the server returns the resource. MPP runs on Tempo. Both let an Agent pay micropayments inline with the request, no account setup, no out-of-band billing reconciliation. Whichever one the Agent already speaks, Tack accepts.
Taiko is backing Tack as a launch partner. x402 is supported on Taiko from the day Tack opens, which means any Agent already settling payments on Taiko can pay Tack the same way it pays anything else, with no new infrastructure to stand up. Base and Tempo round out the launch rails.
This is the part that makes Tack useful in practice. Storage is not the hard problem. Storage that an autonomous Agent can pay for, on its own, in the same call, without a human pre-funding anything, is the hard problem.
Why it shipped first
Inference Room is a launchpad with one rule: every launch is also a release. There are no waitlists, no demo videos for things that do not exist, no rollouts in stages. Anything that cannot open on the day either gets cut down to the part that can or waits. Tack opening is what that rule looks like in practice. The article you are reading goes out on the same day as the product, and the product works in a browser, and the link below points to it.
Tack is the smallest useful version of the storage primitive Agents need. It does one thing, takes payment for that one thing, returns an address. It is not the only Inference Room launch about Agent payments and it will not be the last, but it is the first, and the reason it is first is that it is finished.
Tack is open at tack.inferenceroom.ai now. The next launches arrive at inferenceroom.ai.
This post is exploratory and does not represent a specific roadmap.